Electric Tables V0.1
Experimenting with personal databases and the web as a texture
I spend all day long slinging URLs around. Mostly, when I copy and paste a URL it’s treated as a string of characters. But you and I know that a URL is heavy. A URL is a representation of a blog post, or a product I want to buy, or a hike I want to go on, or an Airbnb I’m going to book.
URLs are also useful. Opening tabs and browsing the web is essential to task completion. Tab sprawl is a symptom of a basic task: web foraging1.
In short, I spend a lot of both professional and personal time on the web - grabbing, saving, sending and bookmarking URLs.
What if we could work with URLs in a way that embraced their weight. That was designed for web foraging?
Say hello to ⚡ Electric Tables. It’s a little research project and prototype to explore the idea of structured data, personal databases and web as texture.
It’s pretty simple. It looks something like this:
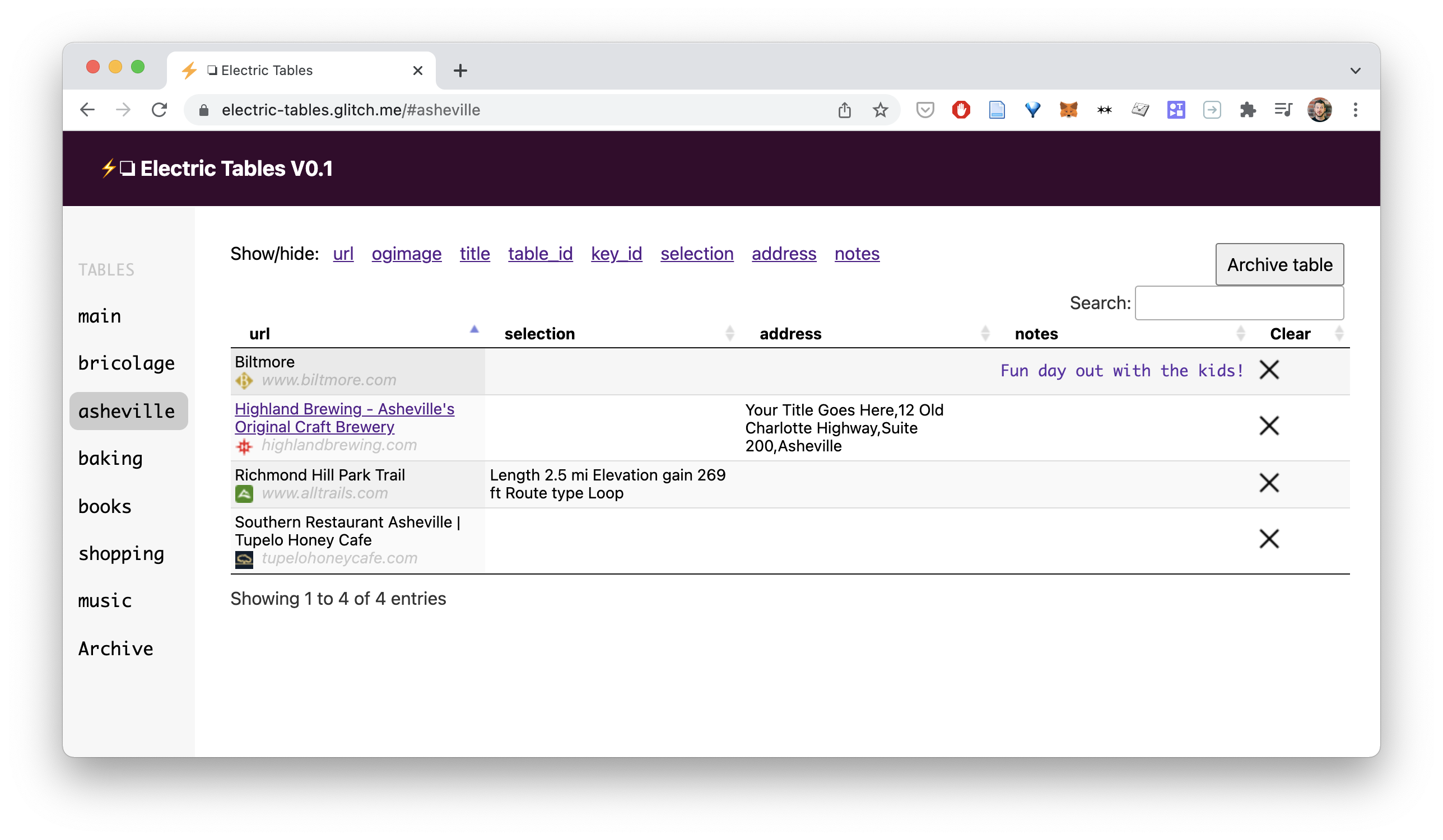
Electric Tables works by taking a URL, extracting some key data and adding it to a table.
It works by using a bookmarklet and local storage. So there’s no login and no database in V0.1.
Simply click it on a page you want to save and you’ll see something like this:
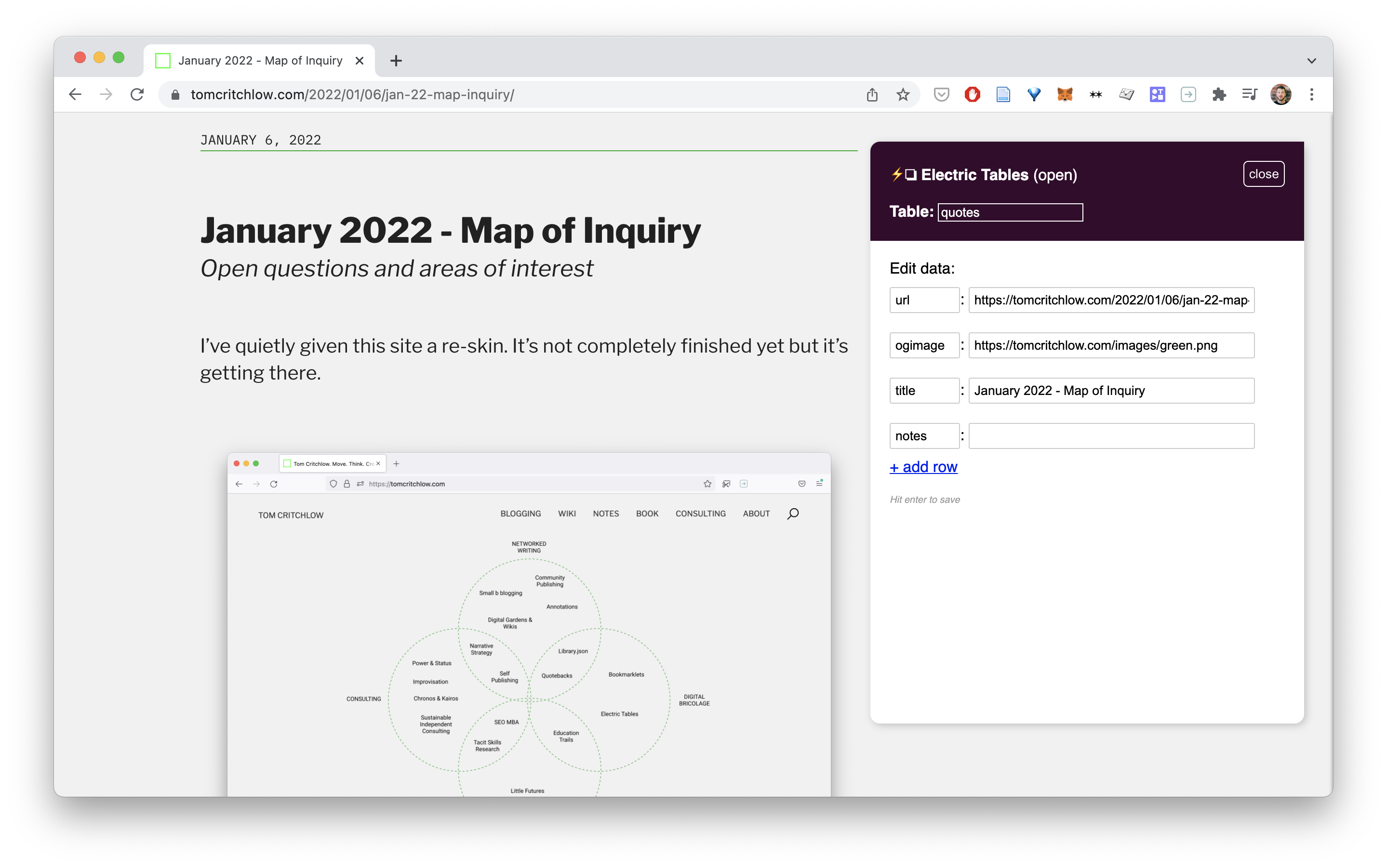
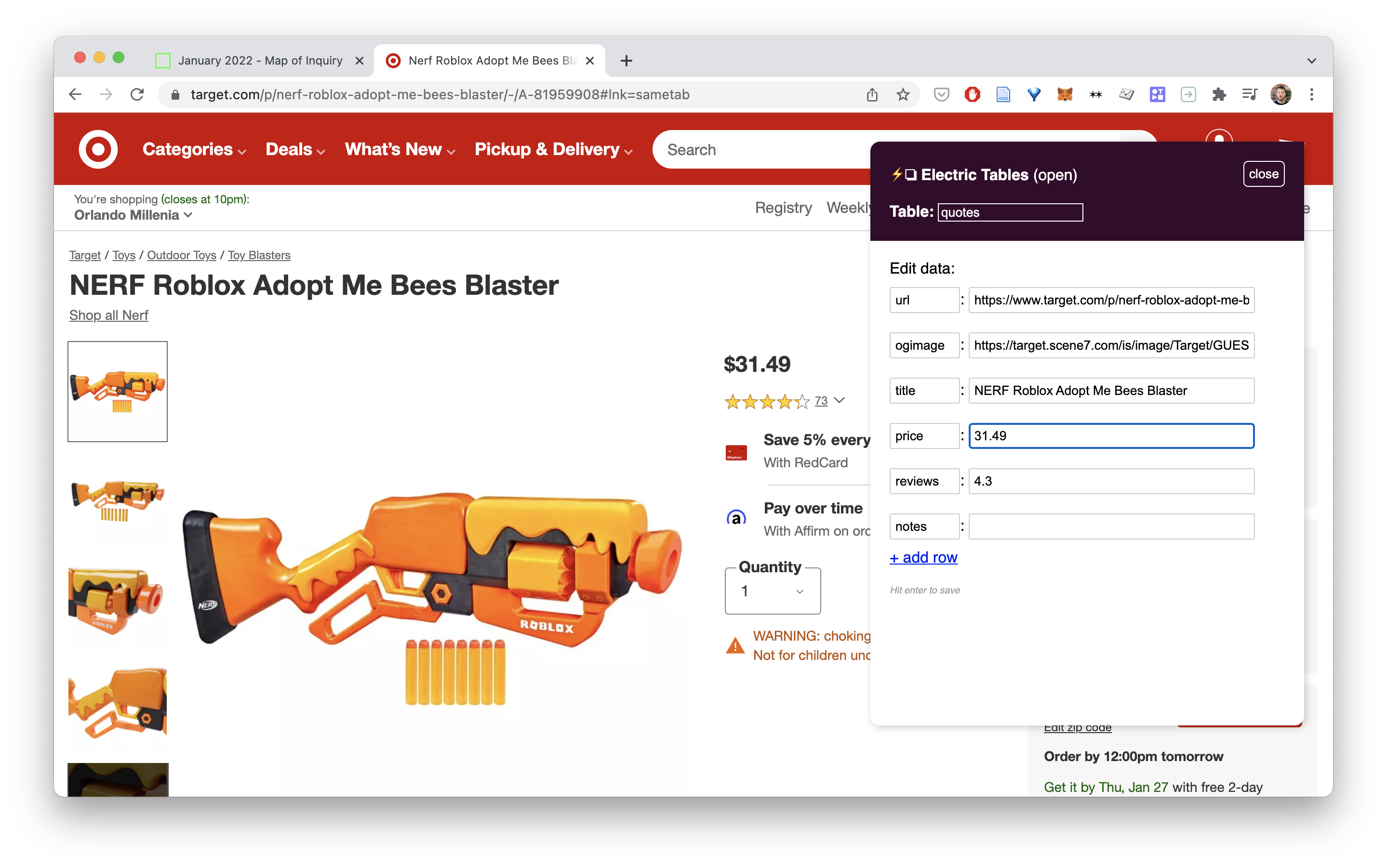
Notice how it automatically extracts basic information like title and image? Neat. When we try it on a Target page for example notice how it grabs the price and review score automatically?
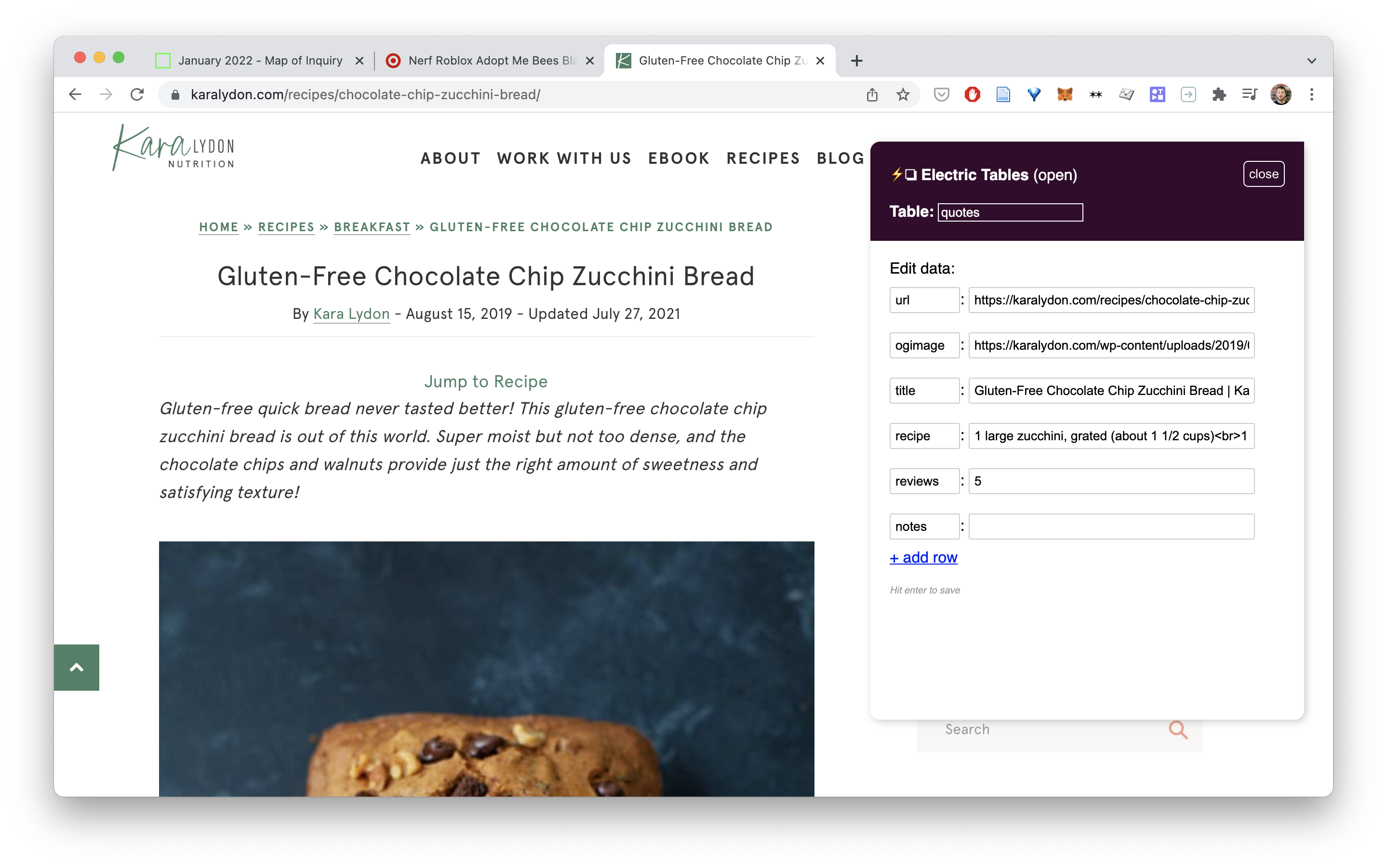
Or when we try it on a recipe page it automatically extracts the ingredients into a list:
You can change which table it saves to in the dropdown at the top (it defaults to the last used). And you can edit or add fields of data by adding rows.
Try it yourself by dragging this bookmarklet to your bookmarks bar:
Then, view your tables here: https://electric-tables.glitch.me/
Or watch the 3 minute demo here:
Some Notes
A few things to note:
- You can add notes against every item in the table. Just click in the “notes” cell and type
- You can move items from one table to another by editing the hidden “table_id” field
- Don’t use this for anything important (yet) - it’s still being tinkered with…
- Desktop only right now (because of the bookmarklet/localstorage constraint)
- All the code is here if you want to poke around (poorly documented right now, sorry! DM me and I can walk you through it)
When a page is saved, it’ll try and grab structured data from the page such as:
- URL, title, open graph image
- Schema data like: price, address, recipe ingredients
- It’ll also save any text you have highlighted on the page into a “selection” field!
Note, because of technical reasons (content security policies) some sites (e.g. Twitter, Airbnb) will add to Electric Tables, but in a new tab instead of using a pop-up and it won’t grab much additional data..
In addition to this (for power users only!) there’s an options page where you can write your own custom selectors:

These are rules that map domain filters to custom extractors. This is useful because data extraction is always going to be fragile. Web pages change. Some pages (e.g. Amazon) are actively hostile to data extraction. And the web is vast and weird. I want Electric Tables to be a general purpose tool. This options page provides a quick and easy-ish way to write your own custom extractors on a domain by domain basis…
Maybe in the future you could imagine sharing / uploading custom extraction lists. Kind of like an open scraping database!
What Electric Tables Could Be
Electric Tables V0.1 is really just a sketch. It’s a working prototype but it’s pretty rough around the edges. It still has bugs and doesn’t really do all the things I’d want it to. But I wanted to release it early to get feedback and figure out what to do with it. Should I invest time in making it robust and polished? Would someone else who can actually code run with it and build a better version?
There are a variety of solutions out there that do things a bit like Electric Tables but none of them seem quite right…
- Spreadsheets are cumbersome and slow. I’ll build a Google Doc to compare things but only when the stakes are high enough… And firing up a new spreadsheet is slooooow. Adding URLs to a spreadsheet is time consuming as you have to copy and paste fields one by one.
- Airtable is perhaps the closest comparison to Electric Tables - allowing for tables of data and some limited web extraction. But again - it feels too heavy for the kinds of lightweight uses I’m proposing…
- Are.na is interesting - it’s the perhaps a close cousin in terms of saving URLs to “tables” (channels in Arena language). Are.na does a little bit of the extraction pulling a screenshot, title etc from the page but doesn’t go far enough (and the UI is clunky as you save over 10-20 URLs into a channel, it’s not really designed for comparing and list making)
- Rows.com is kind of like a supercharged spreadsheet (and I like how they have little tables in the UI vs one infinite canvas) but it’s still too “spreadsheety” and is geared heavily to the enterprise (LinkedIn search, Crunchbase search etc). Still, I like the spirit.
I’m not sure where it goes from here, but here are some directions I’d be excited about:
Hosted & Collaborative
Right now Electric Tables stores data in Chrome localstorage. There’s no database. It’s easy to imagine that this could run on a server where the data extraction is done both client side by the bookmarklet AND server side by fetching and crawling the URL.
Once you have a hosted version and the data stored in a database you can do some key things like collaborate on tables! This is a huge and basic feature that’s just a bit outside of my coding abilities unfortunately. Imagine being able to quickly spin up a table for a list of URLs and just share it by sharing the URL. Whether it’s collaborating on a list of potential Airbnbs or gift ideas for the holidays.
The server side scraping can also do some more heavy lifting - such as store the entire page contents in the database. This enables full text search, the ability to re-crawl URLs and more.
This is all technically very feasible - but requires a lot more infrastructure to build things like login, databases and URL crawling…
Saving & Publishing?
Finally - what if Electric Tables wasn’t just about saving, but about publishing too?
It’s frustrating to me that most CMSs don’t really handle tabluated data. I’m using a static site so it’s even worse but even on this site I do things like maintain a list of books or music in a YAML file format:
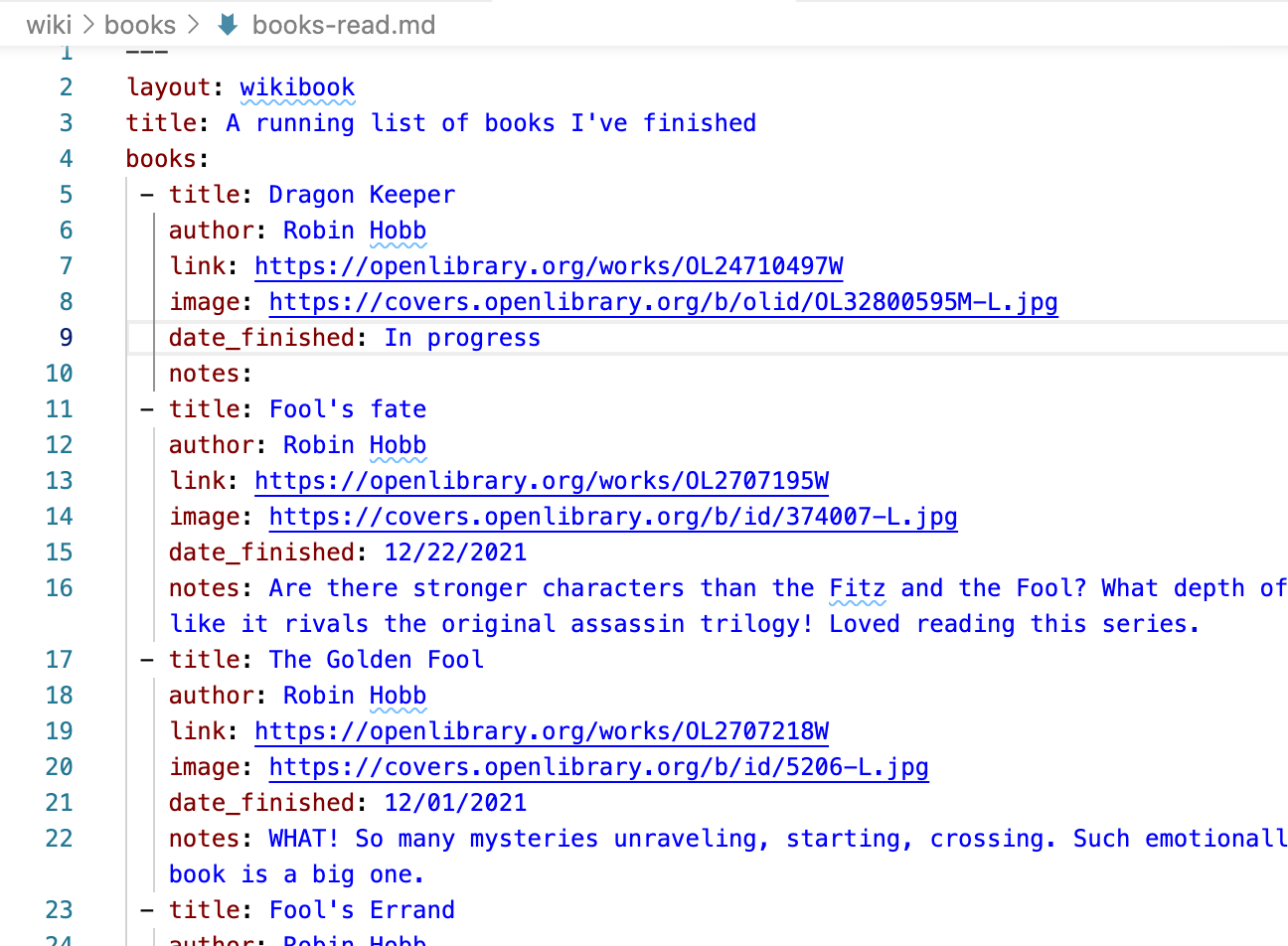
Or, maintain a list of RSS feeds in a spreadsheet:

What if both of these could be powered by Electric Tables? After all what I really want is for them to be my own little table of structured data. I want them to be web native and addressable.
Maybe you can publish any Electric Table as a JSON endpoint?
(What if you could import JSON into an Electric Table endpoint?!)
What’s Interesting? (Is this interesting?)
I’d love your feedback. I’m kind of stalled at the V0.1 phase here - rebuilding this as a hosted NodeJS app feels just about within my skillset but likely a few solid weeks of work (half of which would probably be learning NodeJS!).
Is it worth it? If you’re a real developer want to collaborate?
Do you have ideas for where this could go?
Drop me a note - I’d love to hear your ideas and feedback.
@tomcritchlow (DMs open) or [email protected]
–
Update #1: If you liked this post, check out my next prototype Electric Tables V0.2
-
I first learned of the term “web foraging” in this great paper) where they asked programmers to build a PHP chat room and they spent 19% of their time on the web vs writing code! And that was in 2009! ↩
August 22, 2025
June 27, 2025
Google is Grounded and Needs to Learn How to Soar
March 21, 2025
This post was written by Tom Critchlow - blogger and independent consultant. Subscribe to join my occassional newsletter: