Library JSON - A Proposal for a Decentralized Goodreads
V0.1 for an experimental open bookshelf spec
There’s been a lot of discussion around a “better” GoodReads and at some point almost every side-project-slinger has tried their hand at building a “books website”. Myself included.
Back in 2010 I built a site called 7books - the tagline was playlists for bookworms and it looked like this:

There is a large graveyard of these books sites.
But there are (at least) three fundamental problems with building a GoodReads competitor:
1. Amazon owns the only good book index
As far as I know there is no good reliable book index that’s open. Books come in so many different formats, re-issues, versions, languages and publishers that maintaining a canonical reference for a specific book is very tough.
2. A books website is a cultural black hole
Same is true of music social networks. Cultural black holes. Seductive and imaginary ideas about social networks that just don't work.
— Tom Critchlow (@tomcritchlow) August 22, 2019
It’s one of those alluring ideas that just does. not. work.
3. The only path to monetization is Amazon
Closely related to point #1 - the only (effective) way to monetize a books website is through Amazon. Any books site of meaningful size would get cut from the Amazon affiliate program in a heartbeat as it would compete directly with both Amazon and GoodReads.
But…
Web of Books
On closer examination I realized that I’m not really interested in building a “startup” or a “business” around this - what I really want is
Would love to see a "web of books" emerge from the indie web rather than via fixing goodreads
— Tom Critchlow (@tomcritchlow) September 7, 2019
There are lots of really really great indie sites that maintain structured reading lists. I’ve got a running list in my wiki: web of books. Probably my all time favorite is Mandy’s A Working Library.
Decentralized Architecture
Thinking through building some kind of “web of books” I realized that we could use something similar to RSS to build a kind of decentralized GoodReads powered by indie sites and an underlying easy to parse format.
I created a proof of concept by converting my own bookshelf into a JSON file https://tomcritchlow.com/library.json.
If you think of several sites publishing their bookshelf as a library.json file you can imagine a bookshelf “feed reader” that let’s you keep track of friends bookshelves something like this1:

And combined with a “feed” something like this:
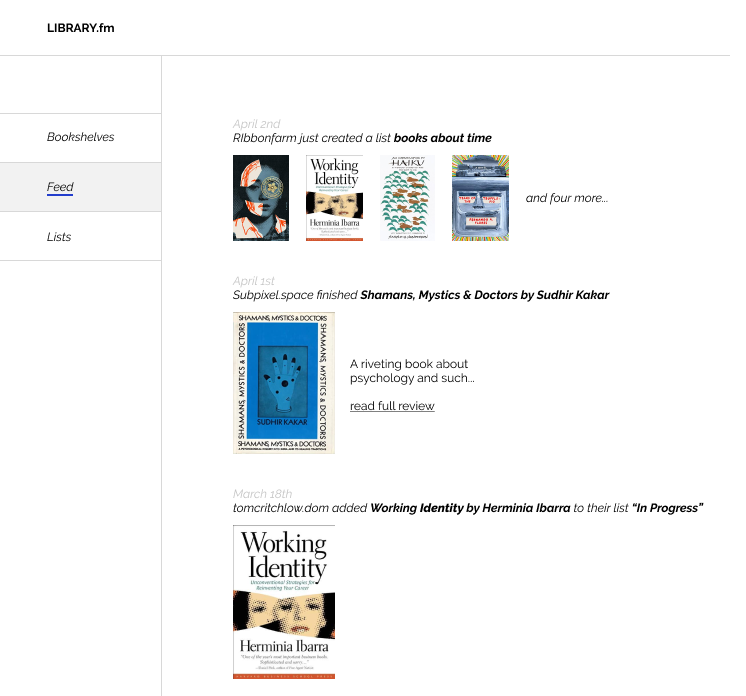
Groups & Control
The great thing about this being an open spec is that people can choose to participate in the centralized GoodReads-esque hub or… not. In fact people can hack on top of it in many ways - extending, modifying and so on.
In particular it would be very easy for a small group of people to form a book club and host a summary view of a handful of library.json files completely independently of any open aggregator.
V0.1 of a library.json spec
So this brings me to my “spec”. Let’s imagine a library.json file that roughly looks like this:
- Title
- URL
- Bio
- Lists
- List
- List
- Lists
Where each book list contains a series of book objects something like this:
- Book
- Title
- Author
- URL
- Date_finished
- ID
- Notes (can be text or a link to a full review/note)
I created some dummy example files in this gist:
Feedback? Next?
So where to next? Three obvious things:
- Further research into a universal book ID solution. Without it this whole idea is going to be shaky ground.
- Building an MVP of the feed reader experience slurping in some sample library.json files
- Gather feedback on the json spec above
If you are interested in building something in this space and/or maintain a page that’s part of the “web of books” I’d love to hear from you on the above proposal.
–
Update #1 - Ravern Koh has built a working proof of concept parser! This is lovely and shows the instant power in a kind of open remixable format:
Have created a quick client for the libary.json files at https://t.co/nAeYTQhM4Y!
— Ravern Koh (@ravernkoh) April 16, 2020
Some samples:
- https://t.co/6Mn62YfpAn
- https://t.co/Ire3MVGqfr
- https://t.co/Z0Yw6uqLJH
For example - here’s my bookshelf displayed on Ravern’s tool. How cool is that! The ability to easily and quickly hack on top of this is super fun. Thanks Ravern!
–
Update #2 - Ravern also had the great suggestion to build the list of people (urls) you follow into the spec… I think that’s a pretty great idea that I will loop back in:
This is a great idea.
— Ravern Koh (@ravernkoh) April 16, 2020
This still requires some kind of centralised listing of library files though. What if instead we added a "following" section where you own library contains links to the libraries of others?
Clients can then build "webs" starting from a seed file
–
Update #3 - Matt has posted a really thoughtful reply proposing building this all as an extension of RSS: Re Tom Critchlow’s proposal for a decentralised Goodreads-like system, how about using RSS?.
Having built my own RSS feed reader already I’m very wary of RSS - it’s battle tested yes but also just one massive clusterf&%$. Parsing and understanding RSS is much harder than JSON (imho!). But - Matt raises some good points and I do like the OPML version of aggregating bookfeeds… Lots of exisiting infrastructure and ideas there… Thanks Matt - plenty to chew on here.
–
Update #4 - Via twitter I found Tom’s bookshelf and his goodreads CSV to yaml converter!! I tagged him and he posted a lovely reply. I don’t think he saw Matt’s reply yet but he echoed the idea of leveraging Atom/RSS for this. Hmm. That said I do love this quote which strikes to the heart of why I like json here:
That said, the thing that kills the indieweb is too much enthusiasm for specs, too few parsing implementations, and, ironically, too much focus on the ‘indie’ (building complicated self-hosted everything-machines) and not enough on the ‘web’ (noticing if anyone’s using any of the things you built). So if there’s a killer implementation and good content at the start, then momentum would potentially just carry you through.
–
Update #5 - This thread from Cory Doctorow:
Last September, @tomcritchlow proposed a federated, decentralized "web of books" as an alternative to Goodreads, the monopoly platform of booklists owned by the monopoly platform of bookselling.https://t.co/FoBrSOZiyY
— Covered Dish People (@doctorow) April 16, 2020
1/ pic.twitter.com/VWrnG5mVhn
–
Update #6 - Gregor posted some nice thoughts. In particular I’m curious about this JSON file. Not sure where it comes from but looks quite a lot like my library.json file! More exploration needed….
–
Update #7 - Phil posted some great thoughts with a strong book-flex!
Having spent some time writing code to track the past 22-40 years of my reading (22 consistenly, 40 with gaps) I thought I’d share a few things I’ve done or thought about, in terms of the data
! Oh my. Thanks Phil - great insights.
–
Update #8 - Ton Zijlstra has posted up some experimentation with an OPML file implementation! Lovely. Lots to explore here.
-
Not accepting freelance web design gigs atm, sorry. ↩
August 22, 2025
June 27, 2025
Google is Grounded and Needs to Learn How to Soar
March 21, 2025
This post was written by Tom Critchlow - blogger and independent consultant. Subscribe to join my occassional newsletter: